Node.js学习
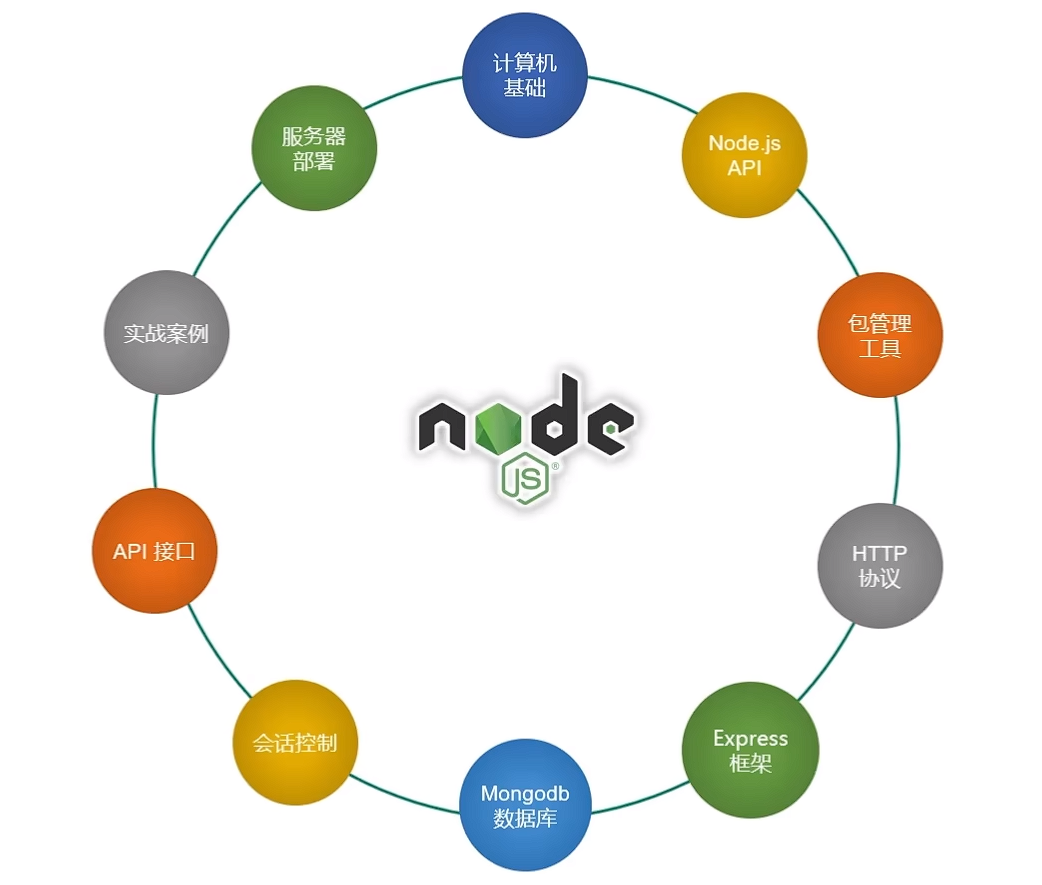
一、学习内容
为框架学习打下基础
二、Node.js注意事项:
不能使用浏览器的api
进程和线程概念


三、Buffer
Buffer(缓冲器)
一、 概念
Buffer 是一个类似于数组的 对象 ,用于表示固定长度的字节序列
Buffer 本质是一段内存空间,专门用来处理 二进制数据 。

二、 特点
Buffer 大小固定且无法调整
Buffer 性能较好,可以直接对计算机内存进行操作
每个元素的大小为 1 字节(byte)

**三、 **使用
3-1. 创建 Buffer
Node.js 中创建 Buffer 的方式主要如下几种:
Buffer.alloc
1
2//创建了一个长度为 10 字节的 Buffer,相当于申请了 10 字节的内存空间,每个字节的值为 0
let buf_1 = Buffer.alloc(10); // 结果为 <Buffer 00 00 00 00 00 00 00 00 00 00>Buffer.allocUnsafe
1
2
3//创建了一个长度为 10 字节的 Buffer,buffer 中可能存在旧的数据, 可能会影响执行结果,所以叫
unsafe
let buf_2 = Buffer.allocUnsafe(10);Buffer.from
1
2
3
4//通过字符串创建 Buffer
let buf_3 = Buffer.from('hello');
//通过数组创建 Buffer
let buf_4 = Buffer.from([105, 108, 111, 118, 101, 121, 111, 117]);
3-2. Buffer 与字符串的转化
我们可以借助 toString 方法将 Buffer 转为字符串
1 | let buf_4 = Buffer.from([105, 108, 111, 118, 101, 121, 111, 117]); |
toString 默认是按照 utf-8 编码方式进行转换的。
3-3 Buffer 的读写
Buffer 可以直接通过 [] 的方式对数据进行处理。
1 | //读取 |
注意:
- 如果修改的数值超过 255 ,则超过 8 位数据会被舍弃
- 一个 utf-8 的字符 一般 占 3 个字节
四、fs模块
fs 全称为 file system ,称之为 文件系统 ,是 Node.js 中的 内置模块 ,可以对计算机中的磁盘进行操作。
本章节会介绍如下几个操作:
- 文件写入
- 文件读取
- 文件移动与重命名
- 文件删除
- 文件夹操作
- 查看资源状态
一、文件写入
文件写入就是将 数据 保存到 文件 中,我们可以使用如下几个方法来实现该效果
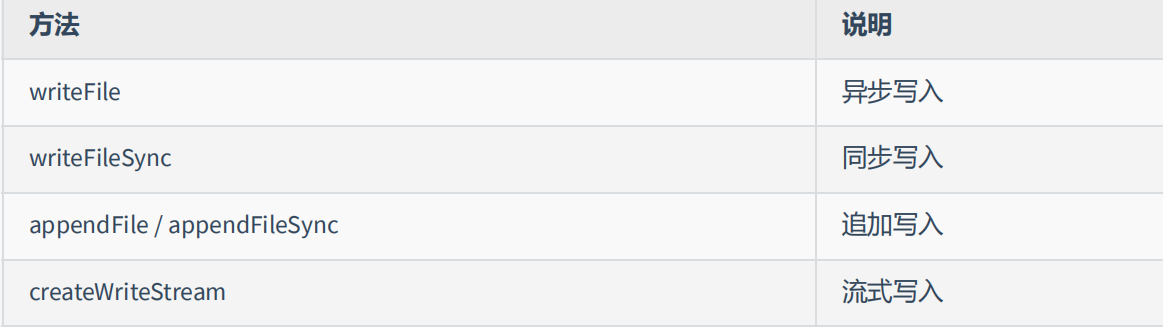
writeFile 异步写入
语法: fs.writeFile(file, data[, options], callback)
参数说明:
- file 文件名
- data 待写入的数据
- options 选项设置 (可选)
- callback 写入回调
返回值: undefined
1 | // require 是 Node.js 环境中的'全局'变量,用来导入模块 |
writeFileSync 同步写入
语法: fs.writeFileSync(file, data[, options])
参数与 fs.writeFile 大体一致,只是没有 callback 参数
返回值: undefined
代码示例:
1 | try{ |
Node.js 中的磁盘操作是由其他 线程 完成的,结果的处理有两种模式:
同步处理 JavaScript 主线程 会等待 其他线程的执行结果,然后再继续执行主线程的代码,效率较低
异步处理 JavaScript 主线程 不会等待 其他线程的执行结果,直接执行后续的主线程代码,效率较好
appendFile / appendFileSync 追加写入
appendFile 作用是在文件尾部追加内容,appendFile 语法与 writeFile 语法完全相同
语法:
fs.appendFile(file, data[, options], callback)
fs.appendFileSync(file, data[, options])
返回值: 二者都为 undefined
1 | fs.appendFile('./座右铭.txt','择其善者而从之,其不善者而改之。', err => { |
createWriteStream 流式写入
语法: fs.createWriteStream(path[, options])
参数说明:
- path 文件路径
- options 选项配置( 可选 )
返回值: Object
1 | let ws = fs.createWriteStream('./观书有感.txt'); |
程序打开一个文件是需要消耗资源的 ,流式写入可以减少打开关闭文件的次数。
流式写入方式适用于 大文件写入或者频繁写入 的场景, writeFile 适合于 写入频率较低的场景
写入文件的场景
文件写入 在计算机中是一个非常常见的操作,下面的场景都用到了文件写入
- 下载文件
- 安装软件
- 保存程序日志,如 Git
- 编辑器保存文件
- 视频录制
当 需要持久化保存数据 的时候,应该想到 文件
二、文件读取
文件读取顾名思义,就是通过程序从文件中取出其中的数据,我们可以使用如下几种方式:
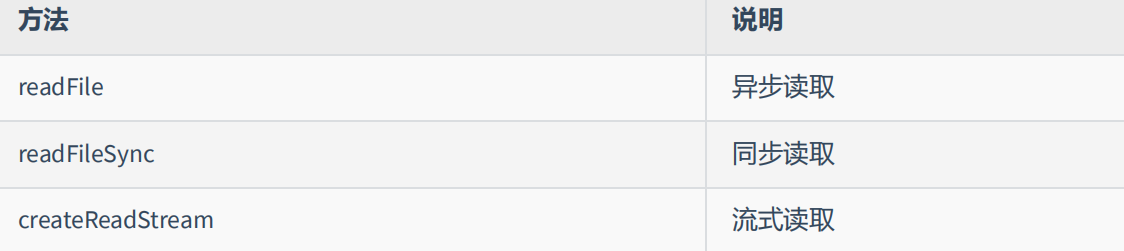
readFile 异步读取
语法: fs.readFile(path[, options], callback)
参数说明:
- path 文件路径
- options 选项配置
- callback 回调函数
返回值: undefined
代码示例:
1 | //导入 fs 模块 |
readFileSync 同步读取
语法: fs.readFileSync(path[, options])
参数说明:
- path 文件路径
- options 选项配置
返回值: string | Buffer
代码示例
1 | let data = fs.readFileSync('./座右铭.txt'); |
createReadStream 流式读取
语法: fs.createReadStream(path[, options])
参数说明:
- path 文件路径
- options 选项配置( 可选 )
返回值: Object
代码示例:
1 | //创建读取流对象 |
读取文件应用场景
- 电脑开机
- 程序运行
- 编辑器打开文件
- 查看图片
- 播放视频
- 播放音乐
- Git 查看日志
- 上传文件
- 查看聊天记录
三、文件移动与重命名
在 Node.js 中,我们可以使用 rename 或 renameSync 来移动或重命名 文件或文件夹
fs.rename(oldPath, newPath, callback)
fs.renameSync(oldPath, newPath)
参数说明:
- oldPath 文件当前的路径
- newPath 文件新的路径
- callback 操作后的回调
代码示例:
1 | fs.rename('./观书有感.txt', './论语/观书有感.txt', (err) =>{ |
四、文件删除
在 Node.js 中,我们可以使用 unlink 或 unlinkSync 来删除文件
fs.unlink(path, callback)
fs.unlinkSync(path)
参数说明:
- path 文件路径
- callback 操作后的回调
代码示例:
1 | const fs = require('fs'); |
五、文件夹操作
借助 Node.js 的能力,我们可以对文件夹进行 创建 、 读取 、 删除 等操作
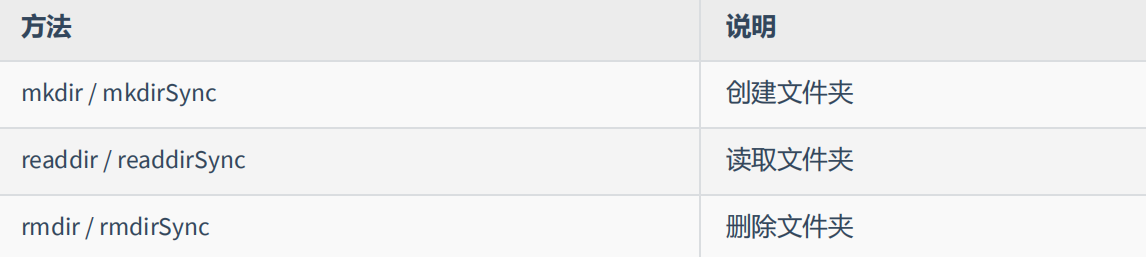
mkdir 创建文件夹
在 Node.js 中,我们可以使用 mkdir 或 mkdirSync 来创建文件夹
fs.mkdir(path[, options], callback)
fs.mkdirSync(path[, options])
参数说明:
- path 文件夹路径
- options 选项配置( 可选 )
- callback 操作后的回调
示例代码:
1 | //异步创建文件夹 |
readdir 读取文件夹
在 Node.js 中,我们可以使用 readdir 或 readdirSync 来读取文件夹
fs.readdir(path[, options], callback)
fs.readdirSync(path[, options])
参数说明:
- path 文件夹路径
- options 选项配置( 可选 )
- callback 操作后的回调
示例代码:
1 | //异步读取 |
rmdir 删除文件夹
在 Node.js 中,我们可以使用 rmdir 或 rmdirSync 来删除文件夹
fs.rmdir(path[, options], callback)
fs.rmdirSync(path[, options])
参数说明:
- path 文件夹路径
- options 选项配置( 可选 )
- callback 操作后的回调
示例代码:
1 | //异步删除文件夹 |
查看资源状态
在 Node.js 中,我们可以使用 stat 或 statSync 来查看资源的详细信息
fs.stat(path[, options], callback)
fs.statSync(path[, options])
参数说明:
- path 文件夹路径
- options 选项配置( 可选 )
- callback 操作后的回调
示例代码:
1 | //异步获取状态 |
1 | 结果值对象结构: |
六、相对路径问题
fs 模块对资源进行操作时,路径的写法有两种:
- 相对路径
- ./座右铭.txt 当前目录下的座右铭.txt
- 座右铭.txt 等效于上面的写法
- ../座右铭.txt 当前目录的上一级目录中的座右铭.txt
- 绝对路径
- D:/Program Files windows 系统下的绝对路径
- /usr/bin Linux 系统下的绝对路径
相对路径中所谓的 当前目录 ,指的是 命令行的工作目录 ,而并非是文件的所在目录
所以当命令行的工作目录与文件所在目录不一致时,会出现一些 BUG
八、__dirname
__dirname 与 require 类似,都是 Node.js 环境中的’全局’变量
__dirname 保存着 当前文件所在目录的绝对路径 ,可以使用 __dirname 与文件名拼接成绝对路径
代码示例:
1 | let data = fs.readFileSync(__dirname + '/data.txt'); |
使用 fs 模块的时候,尽量使用 __dirname 将路径转化为绝对路径,这样可以避免相对路径产生的Bug
五、path模块
一、API
path 模块提供了 操作路径 的功能,我们将介绍如下几个较为常用的几个 API:
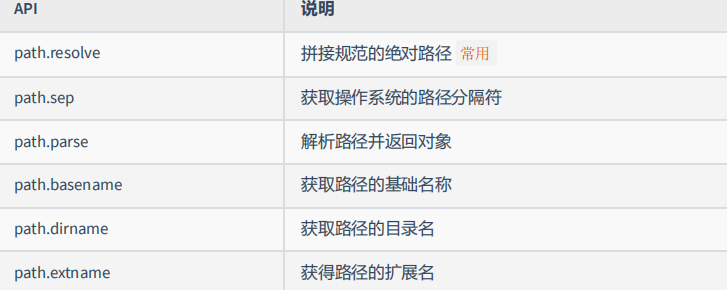
代码示例:
1 | const path = require('path'); |
六、http模块
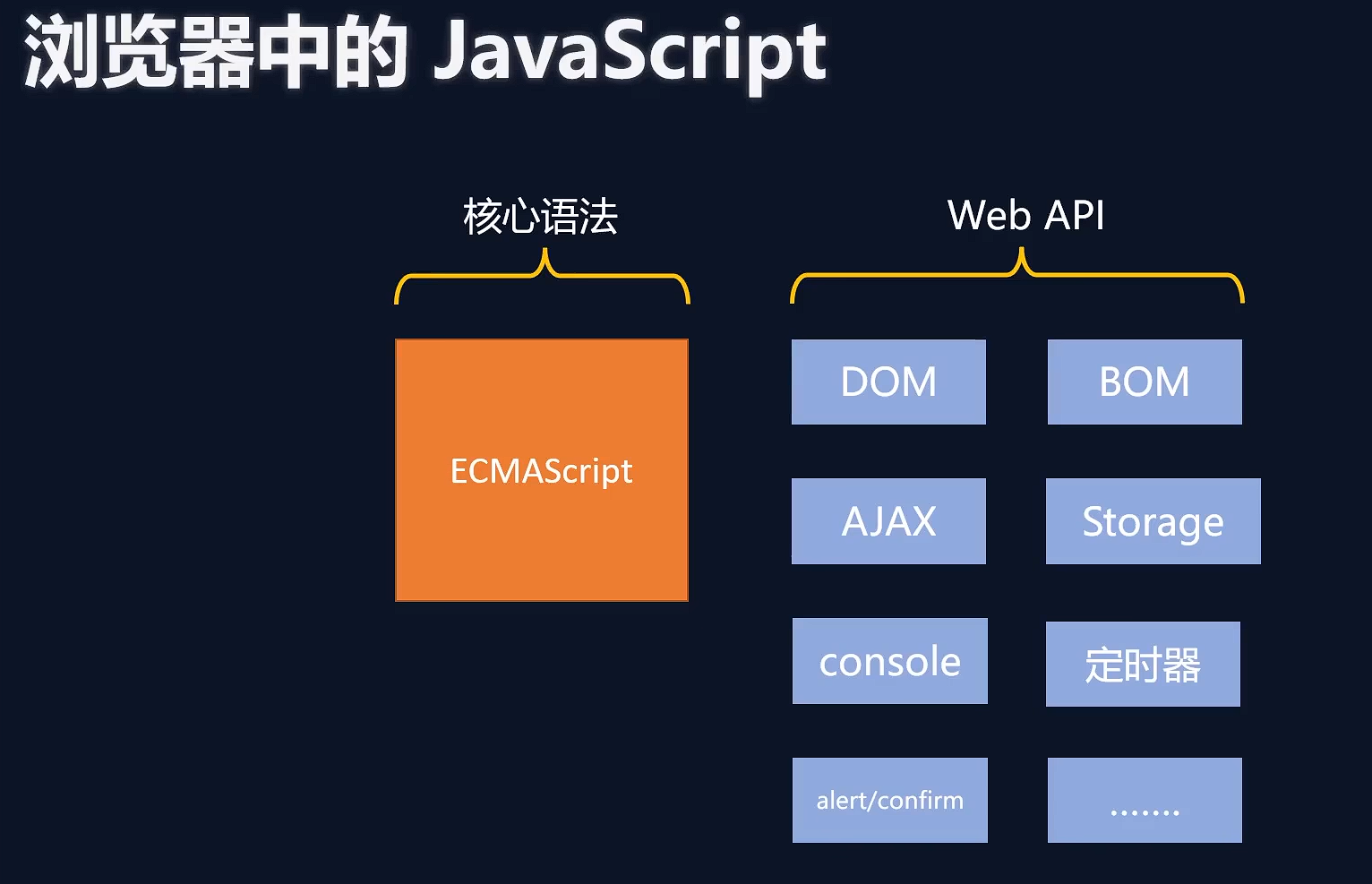
一、概念
HTTP(hypertext transport protocol)协议;中文叫超文本传输协议,是一种基于TCP/IP的应用层通信协议
这个协议详细规定了 浏览器 和万维网 服务器 之间互相通信的规则。
协议中主要规定了两个方面的内容
客户端:用来向服务器发送数据,可以被称之为请求报文
服务端:向客户端返回数据,可以被称之为响应报文
报文:可以简单理解为就是一堆字符串
二、请求报文的组成
- 请求行
- 请求头
- 空行
- 请求体
三、HTTP 的请求行

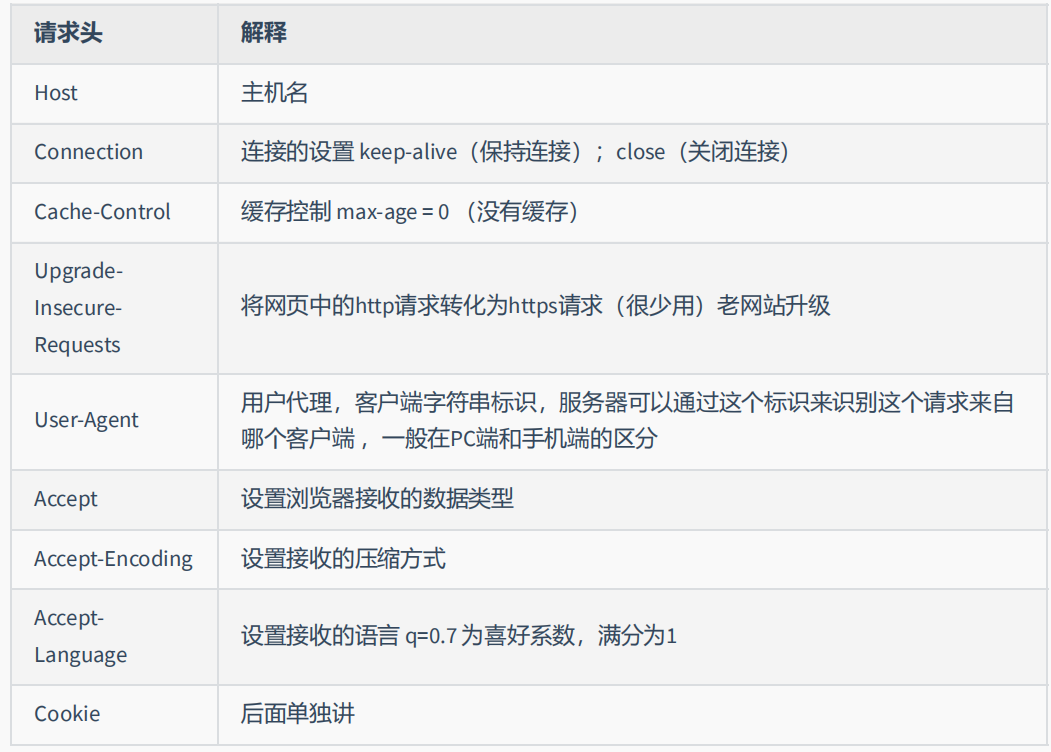
四、HTTP请求头
格式:『头名:头值』
常见的请求头有:
五、HTTP的请求体
请求体内容的格式是非常灵活的,
(可以是空)==> GET请求,
(也可以是字符串,还可以是JSON)===> POST请求
例如:
- 字符串:keywords=手机&price=2000
- JSON:{“keywords”:”手机”,”price”:2000}
六、响应报文的组成
响应行
HTTP/1.1 200 OK

响应状态码和响应字符串关系是一一对应的。
响应头

空行
响应体
响应体内容的类型是非常灵活的,常见的类型有 HTML、CSS、JS、图片、JSON
七、创建 HTTP 服务
使用 nodejs 创建 HTTP 服务
7.1 操作步骤
1 | //1. 导入 http 模块 |
http.createServer 里的回调函数的执行时机: 当接收到 HTTP 请求的时候,就会执行
7.2 测试
浏览器请求对应端口
1 | http://127.0.0.1:9000 |
7.3 注意事项
- 命令行 ctrl + c 停止服务
- 当服务启动后,更新代码 必须重启服务才能生效
- 响应内容中文乱码的解决办法
1 | response.setHeader('content-type','text/html;charset=utf-8'); |
- 端口号被占用
1 | Error: listen EADDRINUSE: address already in use :::9000 |
1)关闭当前正在运行监听端口的服务 ( 使用较多 )
2)修改其他端口号
- HTTP 协议默认端口是 80 。HTTPS 协议的默认端口是 443, HTTP 服务开发常用端口有 3000,
8080,8090,9000 等
如果端口被其他程序占用,可以使用 资源监视器 找到占用端口的程序,然后使用 任务管理器 关闭对应的程序
八、浏览器查看 HTTP 报文
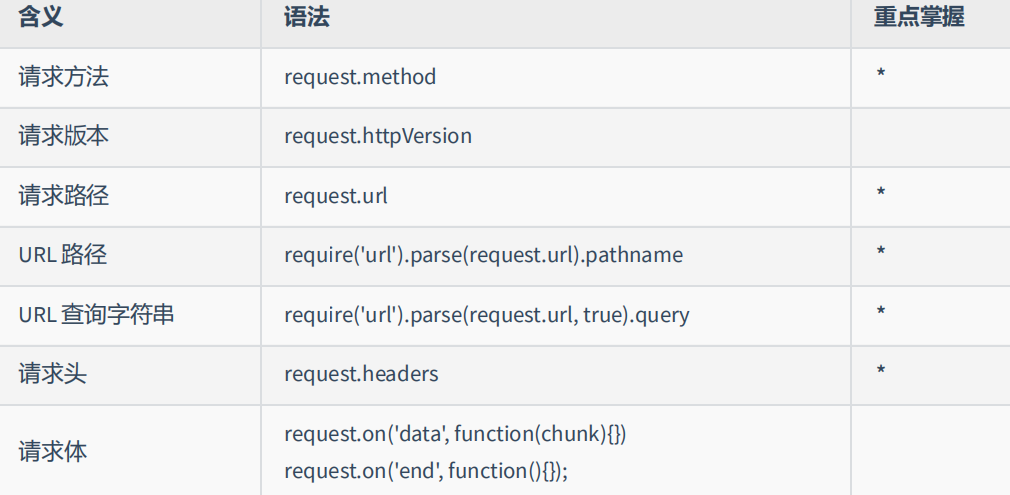
九、获取 HTTP 请求报文
想要获取请求的数据,需要通过 request 对象
注意事项:
- request.url 只能获取路径以及查询字符串,无法获取 URL 中的域名以及协议的内容
- request.headers 将请求信息转化成一个对象,并将属性名都转化成了『小写』
- 关于路径:如果访问网站的时候,只填写了 IP 地址或者是域名信息,此时请求的路径为『 / 』
- 关于 favicon.ico:这个请求是属于浏览器自动发送的请求
十、设置 HTTP 响应报文
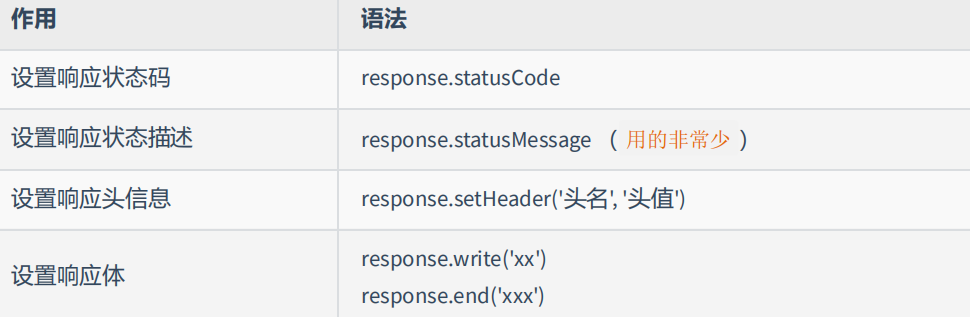
1 | write 和 end 的两种使用情况: |
十一、网页资源的基本加载过程
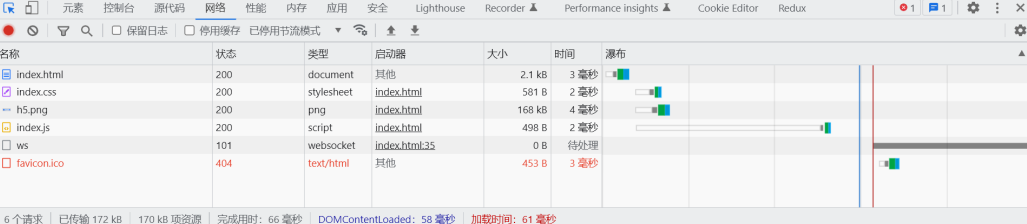
网页资源的加载都是循序渐进的,首先获取 HTML 的内容, 然后解析 HTML 在发送其他资源的请求,如CSS,Javascript,图片等。
十二、静态资源服务
静态资源是指 内容长时间不发生改变的资源 ,例如图片,视频,CSS 文件,JS文件,HTML文件,字体文
件等
动态资源是指 内容经常更新的资源 ,例如百度首页,网易首页,京东搜索列表页面等
12.1 网站根目录或静态资源目录
HTTP 服务在哪个文件夹中寻找静态资源,那个文件夹就是 静态资源目录 ,也称之为 网站根目录
思考:vscode 中使用 live-server 访问 HTML 时, 它启动的服务中网站根目录是谁?
12.2 网页中的 URL
网页中的 URL 主要分为两大类:相对路径与绝对路径
12.2.1 绝对路径
绝对路径可靠性强,而且相对容易理解,在项目中运用较多
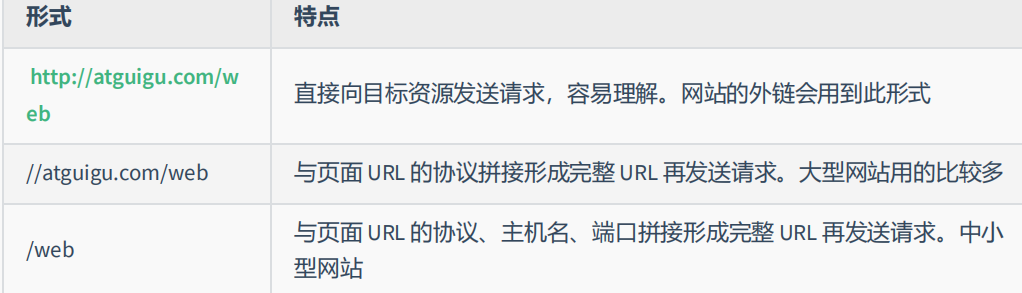
12.2.2 相对路径
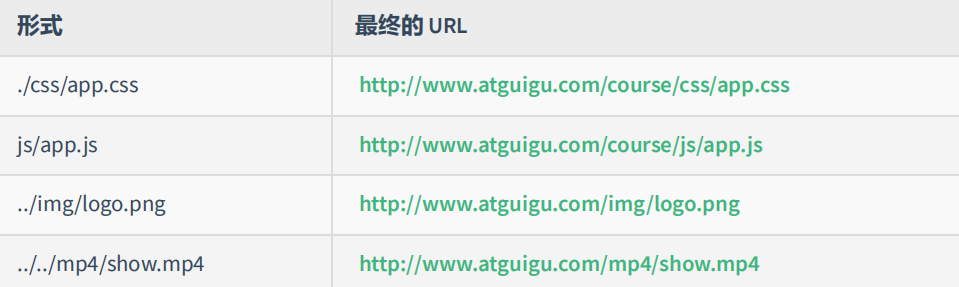
相对路径在发送请求时,需要与当前页面 URL 路径进行 计算 ,得到完整 URL 后,再发送请求,学习阶段用的较多
例如当前网页 url 为 http://www.atguigu.com/course/h5.html
12.2.3 网页中使用 URL 的场景小结
包括但不限于如下场景:
- a 标签 href
- link 标签 href
- script 标签 src
- img 标签 srcvideo audio 标签 src
- form 中的 action
- AJAX 请求中的 URL
12.3 设置资源类型(mime类型)
媒体类型(通常称为 Multipurpose Internet Mail Extensions 或 MIME 类型 )是一种标准,用来表示文档、文件或字节流的性质和格式。
1 | mime 类型结构: [type]/[subType] |
HTTP 服务可以设置响应头 Content-Type 来表明响应体的 MIME 类型,浏览器会根据该类型决定如何处理资源
下面是常见文件对应的 mime 类型
1 | html: 'text/html', |
对于未知的资源类型,可以选择 application/octet-stream 类型,浏览器在遇到该类型的响应时,会对响应体内容进行独立存储,也就是我们常见的 下载 效果
1 | require('http').createServer((request,response)=>{ |
很明显上面的代码,当只要有一个请求路径就需要进行判断,显然这种方式不够完美,那么我们需要封装
1 | require('http').createServer((request,response)=>{ |
12.4 GET 和 POST 请求场景小结
GET 请求的情况:
- 在地址栏直接输入 url 访问
- 点击 a 链接
- link 标签引入 css
- script 标签引入 js
- img 标签引入图片
- form 标签中的 method 为 get (不区分大小写)
- ajax 中的 get 请求
POST 请求的情况:
- form 标签中的 method 为 post(不区分大小写)
- AJAX 的 post 请求
十三、GET和POST请求的区别
GET 和 POST 是 HTTP 协议请求的两种方式。
- GET 主要用来获取数据,POST 主要用来提交数据
- GET 带参数请求是将参数缀到 URL 之后,在地址栏中输入 url 访问网站就是 GET 请求,POST 带参数请求是将参数放到请求体中
- POST 请求相对 GET 安全一些,因为在浏览器中参数会暴露在地址栏
- GET 请求大小有限制,一般为 2K,而 POST 请求则没有大小限制
七、模块化
一、介绍
1.1 什么是模块化与模块 ?
将一个复杂的程序文件依据一定规则(规范)拆分成多个文件的过程称之为 模块化
其中拆分出的 每个文件就是一个模块 ,模块的内部数据是私有的,不过模块可以暴露内部数据以便其他模块使用
1.2 什么是模块化项目 ?
编码时是按照模块一个一个编码的, 整个项目就是一个模块化的项目
1.3 模块化好处
下面是模块化的一些好处:
- 防止命名冲突
- 高复用性
- 高维护性
二、模块暴露数据
2.1 模块初体验
可以通过下面的操作步骤,快速体验模块化
创建 me.js
1
2
3
4
5
6//声明函数
function tiemo(){
console.log('贴膜....');
}
//暴露数据
module.exports = tiemo;创建 index.js
1 | //导入模块 |
2.2 暴露数据
模块暴露数据的方式有两种:
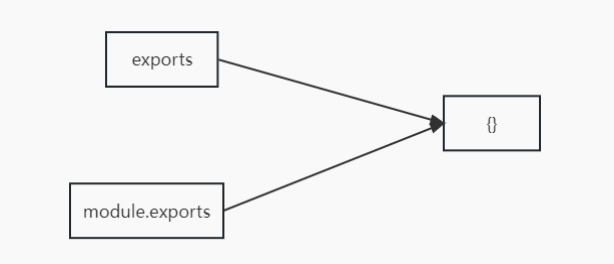
- module.exports = value
- exports.name = value

三、导入(引入)模块
在模块中使用 require 传入文件路径即可引入文件
1 | const test = require('./me.js'); |
require 使用的一些注意事项:
对于自己创建的模块,导入时路径建议写 相对路径 ,且不能省略 ./ 和 ../
js 和 json 文件导入时可以不用写后缀,c/c++编写的 node 扩展文件也可以不写后缀,但是一般用不到
如果导入其他类型的文件,会以 js 文件进行处理
如果导入的路径是个文件夹,则会 首先 检测该文件夹下
package.json文件中 main 属性对应的文件,如果存在则导入,反之如果文件不存在会报错。如果main属性不存在,或者package.json不存在,则会尝试导入文件夹下的index.js和index.json,如果还是没找到,就会报错导入 node.js 内置模块时,直接
require模块的名字即可,无需加 ./ 和 ../
四、导入模块的基本流程
require 导入 自定义模块 的基本流程
- 将相对路径转为绝对路径,定位目标文件
- 缓存检测
- 读取目标文件代码
- 包裹为一个函数并执行(自执行函数)。通过
arguments.callee.toString()查看自执行函数 - 缓存模块的值
- 返回
module.exports的值
五、CommonJS规范
module.exports 、 exports 以及 require 这些都是CommonJS模块化规范中的内容。
而 Node.js 是实现了 CommonJS 模块化规范,二者关系有点像 JavaScript 与 ECMAScript
八、包管理工具
一、概念介绍
1.1 包是什么
『包』英文单词是 package ,代表了一组特定功能的源码集合
1.2 包管理工具
管理『包』的应用软件,可以对「包」进行 下载安装 , 更新 , 删除 , 上传 等操作
借助包管理工具,可以快速开发项目,提升开发效率
包管理工具是一个通用的概念,很多编程语言都有包管理工具,所以 掌握好包管理工具非常重要
1.3 常用的包管理工具
下面列举了前端常用的包管理工具
- npm
- yarn
- cnpm
二、npm
npm 全称 Node Package Manager ,翻译为中文意思是『Node 的包管理工具』
npm 是 node.js 官方内置的包管理工具,是 必须要掌握住的工具
2.1 npm 的安装
node.js 在安装时会 自动安装 npm ,所以如果你已经安装了 node.js,可以直接使用 npm
可以通过 npm -v 查看版本号测试,如果显示版本号说明安装成功,反之安装失败
2.2 npm 基本使用
2.2.1 初始化
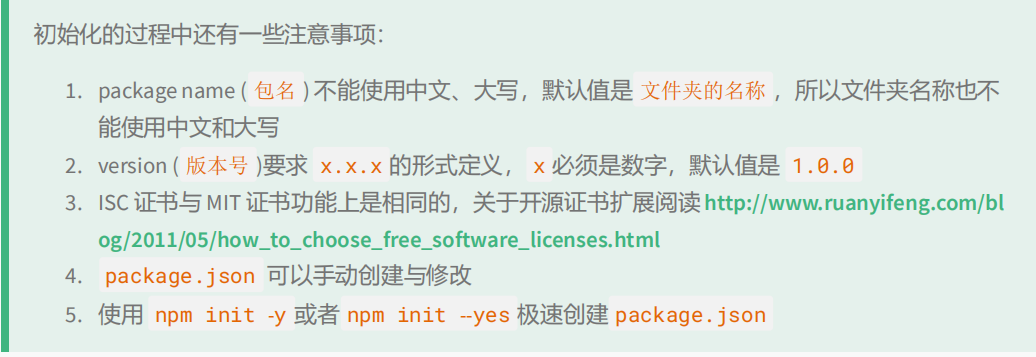
创建一个空目录,然后以此目录作为工作目录 启动命令行工具 ,执行 npm init
npm init 命令的作用是将文件夹初始化为一个『包』, 交互式创建 package.json 文件
package.json 是包的配置文件,每个包都必须要有 package.json
package.json 内容示例:
1 | { |
2.2.2 搜索包
搜索包的方式有两种
- 命令行 『
npm s/search关键字』 - 网站搜索 网址是 https://www.npmjs.com/
2.2.3 下载安装包
我们可以通过 npm install 和 npm i 命令安装包
1 | # 格式 |
运行之后文件夹下会增加两个资源
node_modules文件夹 存放下载的包package-lock.json包的锁文件 ,用来锁定包的版本

2.2.4 require 导入 npm 包基本流程
- 在当前文件夹下 node_modules 中寻找同名的文件夹
- 在上级目录中下的 node_modules 中寻找同名的文件夹,直至找到磁盘根目录
2.3 生产环境与开发环境
开发环境是程序员 专门用来写代码 的环境,一般是指程序员的电脑,开发环境的项目一般 只能程序员自己访问
生产环境是项目 代码正式运行 的环境,一般是指正式的服务器电脑,生产环境的项目一般 每个客户都可以访问
2.4 生产依赖与开发依赖
我们可以在安装时设置选项来区分 依赖的类型 ,目前分为两类:


2.5 全局安装
我们可以执行安装选项 -g 进行全局安装
1 | npm i -g nodemon |
全局安装完成之后就可以在命令行的任何位置运行 nodemon 命令
该命令的作用是 自动重启 node 应用程序

2.5.1环境变量Path
Path 是操作系统的一个环境变量,可以设置一些文件夹的路径,在当前工作目录下找不到可执行文件时,就会在环境变量 Path 的目录中挨个的查找,如果找到则执行,如果没有找到就会报错

2.6 安装包依赖
在项目协作中有一个常用的命令就是 npm i ,通过该命令可以依据 package.json 和 packagelock.json 的依赖声明安装项目依赖
1 | npm i |
2.7 安装指定版本的包
项目中可能会遇到版本不匹配的情况,有时就需要安装指定版本的包,可以使用下面的命令
1 | ## 格式 |
2.8 删除依赖
项目中可能需要删除某些不需要的包,可以使用下面的命令
1 | ## 局部删除 |
2.9 配置命令别名
通过配置命令别名可以更简单的执行命令
配置 package.json 中的 scripts 属性
1 | { |
配置完成之后,可以使用别名执行命令
1 | npm run server |
不过 start 别名比较特别,使用时可以省略 run

三、cnpm
3.1 介绍
cnpm 是一个淘宝构建的 npmjs.com 的完整镜像,也称为『淘宝镜像』,网址https://npmmirror.com/
cnpm 服务部署在国内 阿里云服务器上 , 可以提高包的下载速度
官方也提供了一个全局工具包 cnpm ,操作命令与 npm 大体相同
3.2 安装
我们可以通过 npm 来安装 cnpm 工具
1 | npm install -g cnpm --registry=https://registry.npmmirror.com |
3.3 操作命令
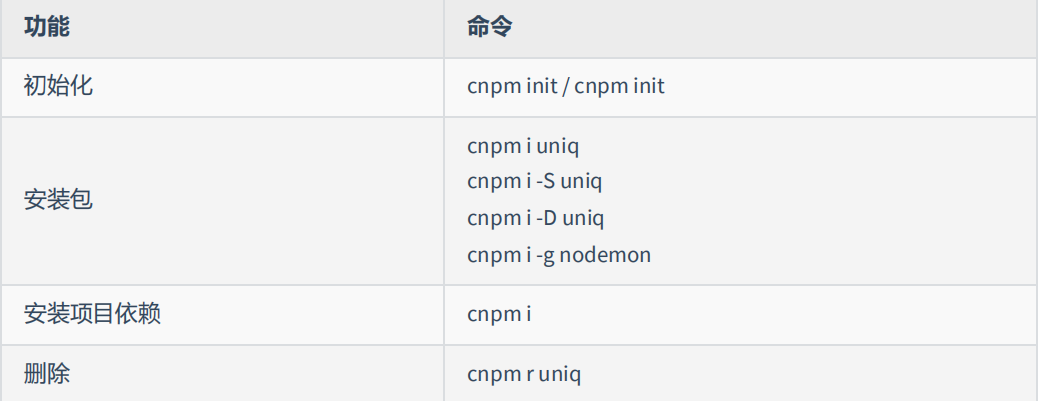
3.4 npm 配置淘宝镜像
用 npm 也可以使用淘宝镜像,配置的方式有两种
- 直接配置
- 工具配置
3.4.1 直接配置
执行如下命令即可完成配置
1 | npm config set registry https://registry.npmmirror.com/ |
3.4.2 工具配置
使用 nrm 配置 npm 的镜像地址 npm registry manager
- 安装 nrm
1 | npm i -g nrm |
- 修改镜像
1 | nrm use taobao |
- 检查是否配置成功(选做)
1 | npm config list |
检查 registry 地址是否为 https://registry.npmmirror.com/ , 如果 是 则表明成功
虽然 cnpm 可以提高速度,但是 npm 也可以通过淘宝镜像进行加速,所以 npm 的使用率还是高于 cnpm
四、yarn
4.1 yarn 介绍
yarn 是由 Facebook 在 2016 年推出的新的 Javascript 包管理工具,官方网址:https://yarnpkg.com/
4.2 yarn 特点
yarn 官方宣称的一些特点
- 速度超快:yarn 缓存了每个下载过的包,所以再次使用时无需重复下载。 同时利用并行下载以最大化资源利用率,因此安装速度更快
- 超级安全:在执行代码之前,yarn 会通过算法校验每个安装包的完整性
- 超级可靠:使用详细、简洁的锁文件格式和明确的安装算法,yarn 能够保证在不同系统上无差异的工作
4.3 yarn 安装
我们可以使用 npm 安装 yarn
1 | npm i -g yarn |
4.4 yarn 常用命令
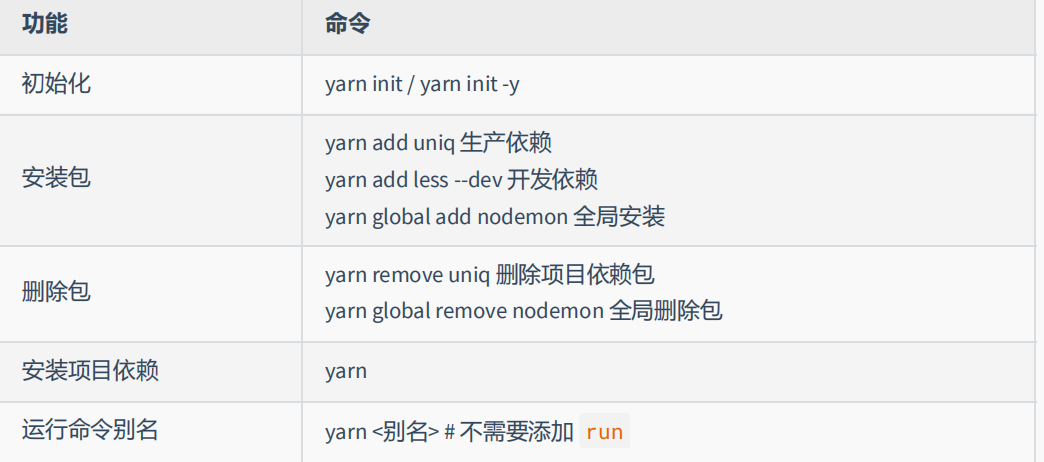
4.5 yarn 配置淘宝镜像
可以通过如下命令配置淘宝镜像
1 | yarn config set registry https://registry.npmmirror.com/ |
可以通过 yarn config list 查看 yarn 的配置项
4.6 npm 和 yarn 选择
大家可以根据不同的场景进行选择
- 个人项目
如果是个人项目, 哪个工具都可以 ,可以根据自己的喜好来选择
- 公司项目
如果是公司要根据项目代码来选择,可以 通过锁文件判断 项目的包管理工具
- npm 的锁文件为 package-lock.json
- yarn 的锁文件为 yarn.lock
五、管理发布包
5.1 创建与发布
我们可以将自己开发的工具包发布到 npm 服务上,方便自己和其他开发者使用,操作步骤如下:
- 创建文件夹,并创建文件 index.js, 在文件中声明函数,使用 module.exports 暴露
- npm 初始化工具包,package.json 填写包的信息 (包的名字是唯一的)
- 注册账号 https://www.npmjs.com/signup
- 激活账号 ( 一定要激活账号 )
- 修改为官方的官方镜像 (命令行中运行 nrm use npm )
- 命令行下 npm login 填写相关用户信息
- 命令行下 npm publish 提交包 👌
5.2 更新包
后续可以对自己发布的包进行更新,操作步骤如下
- 更新包中的代码
- 测试代码是否可用
- 修改 package.json 中的版本号
- 发布更新
1 | npm publish |
5.3 删除包
执行如下命令删除包
1 | npm unpublish --force |
删除包需要满足一定的条件,https://docs.npmjs.com/policies/unpublish
- 你是包的作者
- 发布小于 24 小时
- 大于 24 小时后,没有其他包依赖,并且每周小于 300 下载量,并且只有一个维护者
六、扩展内容
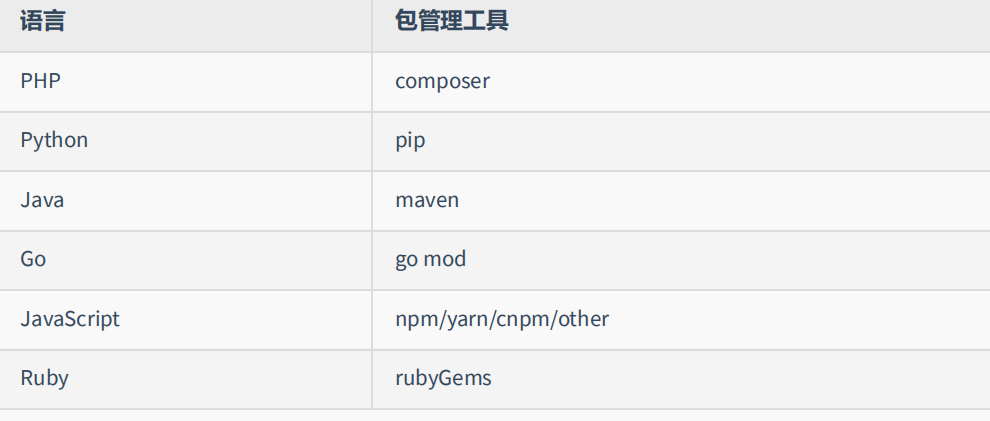
在很多语言中都有包管理工具,比如: